Radial velocity fitting#
import exoplanet
exoplanet.utils.docs_setup()
print(f"exoplanet.__version__ = '{exoplanet.__version__}'")
exoplanet.__version__ = '0.5.4.dev27+g75d7fcc'
In this case study, we will demonstrate how to fit radial velocity observations of an exoplanetary system using exoplanet. We will follow the getting started tutorial from the excellent RadVel package where they fit for the parameters of the two planets in the K2-24 system.
First, let’s download the data from RadVel:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
url = "https://raw.githubusercontent.com/California-Planet-Search/radvel/master/example_data/epic203771098.csv"
data = pd.read_csv(url, index_col=0)
x = np.array(data.t)
y = np.array(data.vel)
yerr = np.array(data.errvel)
# Compute a reference time that will be used to normalize the trends model
x_ref = 0.5 * (x.min() + x.max())
# Also make a fine grid that spans the observation window for plotting purposes
t = np.linspace(x.min() - 5, x.max() + 5, 1000)
plt.errorbar(x, y, yerr=yerr, fmt=".k")
plt.xlabel("time [days]")
_ = plt.ylabel("radial velocity [m/s]")
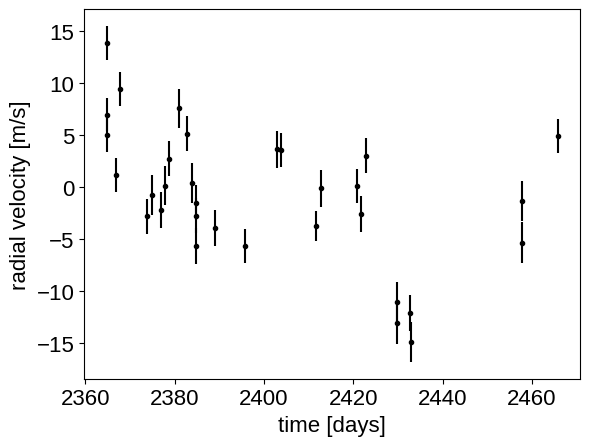
Now, we know the periods and transit times for the planets from the K2 light curve, so let’s start by using the :func:exoplanet.estimate_semi_amplitude function to estimate the expected RV semi-amplitudes for the planets.
import exoplanet as xo
periods = [20.8851, 42.3633]
period_errs = [0.0003, 0.0006]
t0s = [2072.7948, 2082.6251]
t0_errs = [0.0007, 0.0004]
Ks = xo.estimate_semi_amplitude(periods, x, y, yerr, t0s=t0s)
print(Ks, "m/s")
[5.05069163 5.50983542] m/s
0.5 * (
np.log(np.array(periods) + np.array(period_errs))
- np.log(np.array(periods) - np.array(period_errs))
)
array([1.43643076e-05, 1.41632026e-05])
np.array(period_errs) / np.array(periods)
array([1.43643076e-05, 1.41632026e-05])
The radial velocity model in PyMC3#
Now that we have the data and an estimate of the initial values for the parameters, let’s start defining the probabilistic model in PyMC3. First, we’ll define our priors on the parameters:
import pymc3 as pm
import pymc3_ext as pmx
import aesara_theano_fallback.tensor as tt
with pm.Model() as model:
# Gaussian priors based on transit data (from Petigura et al.)
t0 = pm.Normal("t0", mu=np.array(t0s), sd=np.array(t0_errs), shape=2)
logP = pm.Normal(
"logP",
mu=np.log(periods),
sd=np.array(period_errs) / np.array(periods),
shape=2,
testval=np.log(periods),
)
P = pm.Deterministic("P", tt.exp(logP))
# Wide log-normal prior for semi-amplitude
logK = pm.Normal(
"logK", mu=np.log(Ks), sd=2.0, shape=2, testval=np.log(Ks)
)
# Eccentricity & argument of periasteron
ecs = pmx.UnitDisk("ecs", shape=(2, 2), testval=0.01 * np.ones((2, 2)))
ecc = pm.Deterministic("ecc", tt.sum(ecs**2, axis=0))
omega = pm.Deterministic("omega", tt.arctan2(ecs[1], ecs[0]))
xo.eccentricity.vaneylen19(
"ecc_prior", multi=True, shape=2, fixed=True, observed=ecc
)
# Jitter & a quadratic RV trend
logs = pm.Normal("logs", mu=np.log(np.median(yerr)), sd=5.0)
trend = pm.Normal("trend", mu=0, sd=10.0 ** -np.arange(3)[::-1], shape=3)
# Then we define the orbit
orbit = xo.orbits.KeplerianOrbit(period=P, t0=t0, ecc=ecc, omega=omega)
# And a function for computing the full RV model
def get_rv_model(t, name=""):
# First the RVs induced by the planets
vrad = orbit.get_radial_velocity(t, K=tt.exp(logK))
pm.Deterministic("vrad" + name, vrad)
# Define the background model
A = np.vander(t - x_ref, 3)
bkg = pm.Deterministic("bkg" + name, tt.dot(A, trend))
# Sum over planets and add the background to get the full model
return pm.Deterministic("rv_model" + name, tt.sum(vrad, axis=-1) + bkg)
# Define the RVs at the observed times
rv_model = get_rv_model(x)
# Also define the model on a fine grid as computed above (for plotting)
rv_model_pred = get_rv_model(t, name="_pred")
# Finally add in the observation model. This next line adds a new contribution
# to the log probability of the PyMC3 model
err = tt.sqrt(yerr**2 + tt.exp(2 * logs))
pm.Normal("obs", mu=rv_model, sd=err, observed=y)
Now, we can plot the initial model:
plt.errorbar(x, y, yerr=yerr, fmt=".k")
with model:
plt.plot(t, pmx.eval_in_model(model.vrad_pred), "--k", alpha=0.5)
plt.plot(t, pmx.eval_in_model(model.bkg_pred), ":k", alpha=0.5)
plt.plot(t, pmx.eval_in_model(model.rv_model_pred), label="model")
plt.legend(fontsize=10)
plt.xlim(t.min(), t.max())
plt.xlabel("time [days]")
plt.ylabel("radial velocity [m/s]")
_ = plt.title("initial model")
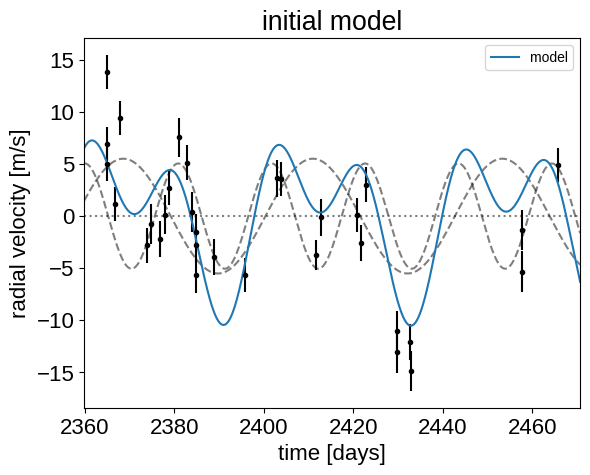
In this plot, the background is the dotted line, the individual planets are the dashed lines, and the full model is the blue line.
It doesn’t look amazing so let’s fit for the maximum a posterior parameters.
with model:
map_soln = pmx.optimize(start=model.test_point, vars=[trend])
map_soln = pmx.optimize(start=map_soln, vars=[t0, trend, logK, logP, logs])
map_soln = pmx.optimize(start=map_soln, vars=[ecs])
map_soln = pmx.optimize(start=map_soln)
optimizing logp for variables: [trend]
message: Optimization terminated successfully.
logp: -68.03907701822229 -> -57.4213493739168
optimizing logp for variables: [logs, logP, logK, trend, t0]
message: Optimization terminated successfully.
logp: -57.4213493739168 -> -51.81968815504227
optimizing logp for variables: [ecs]
message: Optimization terminated successfully.
logp: -51.81968815504227 -> -50.93559539327148
optimizing logp for variables: [trend, logs, ecs, logK, logP, t0]
message: Desired error not necessarily achieved due to precision loss.
logp: -50.93559539327148 -> -50.76564803059732
plt.errorbar(x, y, yerr=yerr, fmt=".k")
plt.plot(t, map_soln["vrad_pred"], "--k", alpha=0.5)
plt.plot(t, map_soln["bkg_pred"], ":k", alpha=0.5)
plt.plot(t, map_soln["rv_model_pred"], label="model")
plt.legend(fontsize=10)
plt.xlim(t.min(), t.max())
plt.xlabel("time [days]")
plt.ylabel("radial velocity [m/s]")
_ = plt.title("MAP model")
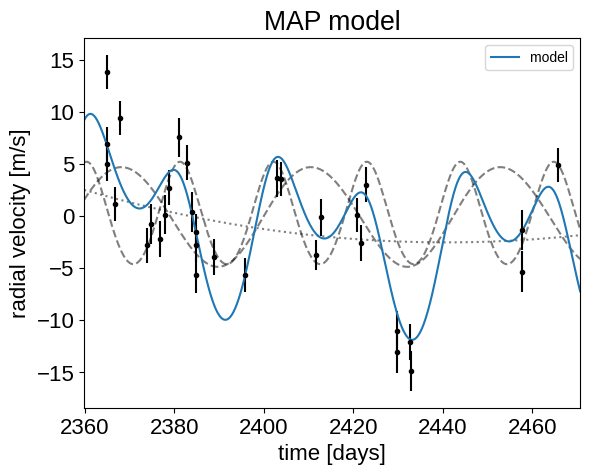
That looks better.
Sampling#
Now that we have our model set up and a good estimate of the initial parameters, let’s start sampling.
There are substantial covariances between some of the parameters so we’ll use the pmx.sample function from pymc3-ext which wraps pm.sample function with some better defaults and tuning strategies.
np.random.seed(42)
with model:
trace = pmx.sample(
tune=1000,
draws=1000,
cores=2,
chains=2,
target_accept=0.9,
return_inferencedata=True,
)
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [trend, logs, ecs, logK, logP, t0]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 11 seconds.
After sampling, it’s always a good idea to do some convergence checks. First, let’s check the number of effective samples and the Gelman-Rubin statistic for our parameters of interest:
import arviz as az
az.summary(
trace, var_names=["trend", "logs", "omega", "ecc", "t0", "logK", "P"]
)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| trend[0] | 0.001 | 0.001 | -0.001 | 0.002 | 0.000 | 0.000 | 1936.0 | 1265.0 | 1.00 |
| trend[1] | -0.042 | 0.023 | -0.086 | 0.002 | 0.001 | 0.000 | 1849.0 | 1189.0 | 1.00 |
| trend[2] | -1.854 | 0.809 | -3.427 | -0.346 | 0.020 | 0.015 | 1591.0 | 1377.0 | 1.00 |
| logs | 1.129 | 0.209 | 0.725 | 1.520 | 0.006 | 0.004 | 1143.0 | 1481.0 | 1.00 |
| omega[0] | -0.023 | 1.212 | -2.439 | 2.590 | 0.026 | 0.023 | 2199.0 | 1899.0 | 1.00 |
| omega[1] | -0.280 | 1.966 | -3.096 | 2.853 | 0.046 | 0.033 | 1928.0 | 1925.0 | 1.00 |
| ecc[0] | 0.083 | 0.086 | 0.000 | 0.266 | 0.004 | 0.002 | 759.0 | 1022.0 | 1.01 |
| ecc[1] | 0.050 | 0.063 | 0.000 | 0.115 | 0.003 | 0.002 | 1101.0 | 555.0 | 1.00 |
| t0[0] | 2072.795 | 0.001 | 2072.794 | 2072.796 | 0.000 | 0.000 | 2039.0 | 1494.0 | 1.00 |
| t0[1] | 2082.625 | 0.000 | 2082.624 | 2082.626 | 0.000 | 0.000 | 2504.0 | 1726.0 | 1.00 |
| logK[0] | 1.513 | 0.243 | 1.065 | 1.910 | 0.008 | 0.006 | 1184.0 | 617.0 | 1.00 |
| logK[1] | 1.489 | 0.266 | 1.008 | 1.954 | 0.008 | 0.005 | 1691.0 | 829.0 | 1.01 |
| P[0] | 20.885 | 0.000 | 20.885 | 20.886 | 0.000 | 0.000 | 2303.0 | 1489.0 | 1.00 |
| P[1] | 42.363 | 0.001 | 42.362 | 42.364 | 0.000 | 0.000 | 2054.0 | 1485.0 | 1.00 |
It looks like everything is pretty much converged here. Not bad for 14 parameters and about a minute of runtime…
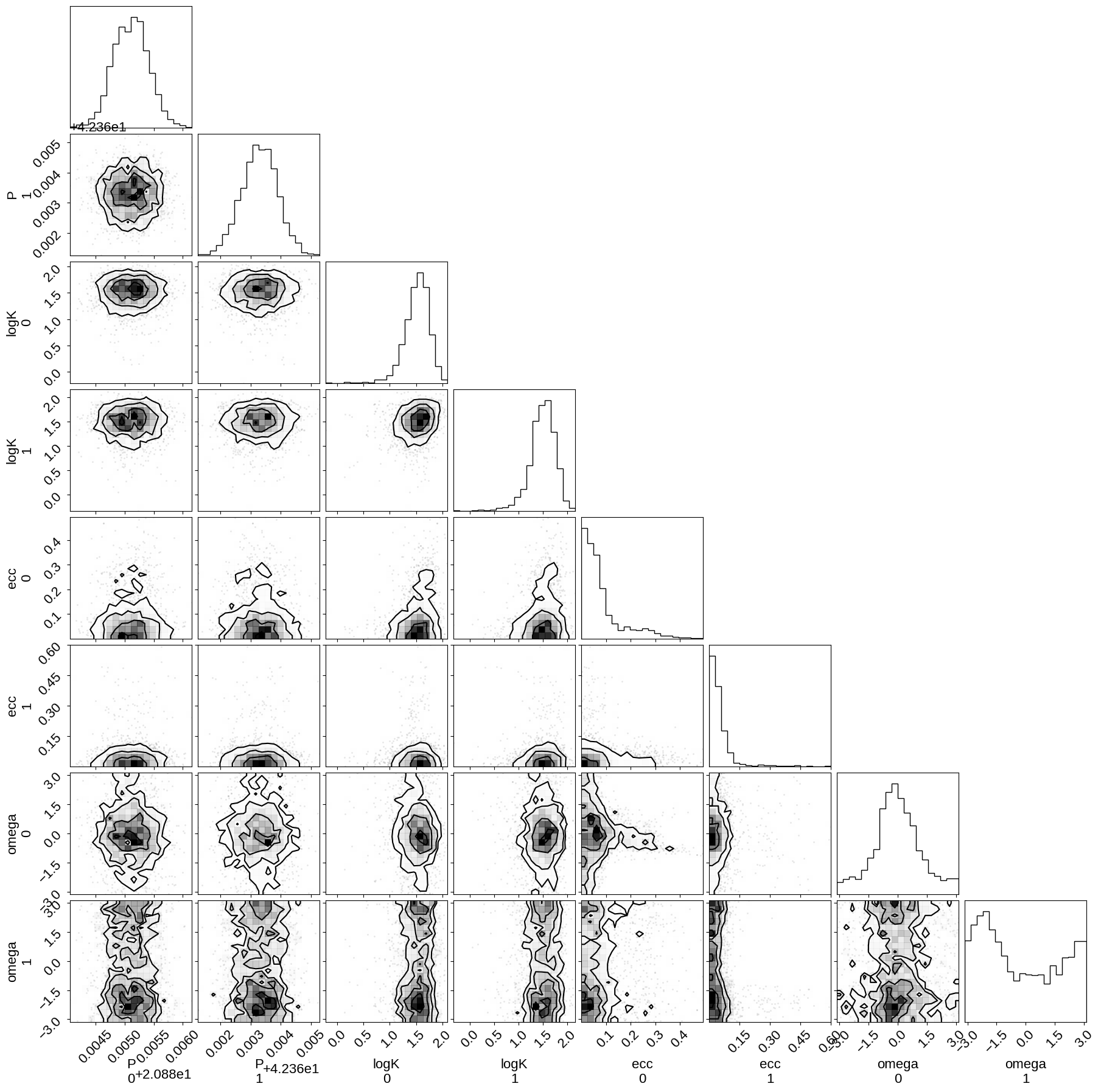
Then we can make a corner plot of any combination of the parameters. For example, let’s look at period, semi-amplitude, and eccentricity:
import corner
with model:
_ = corner.corner(trace, var_names=["P", "logK", "ecc", "omega"])
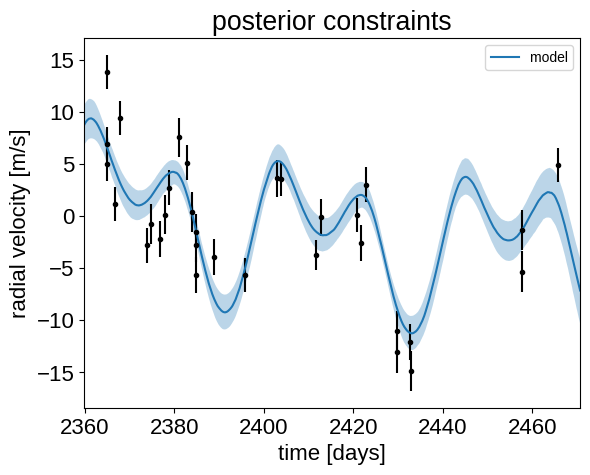
Finally, let’s plot the plosterior constraints on the RV model and compare those to the data:
plt.errorbar(x, y, yerr=yerr, fmt=".k")
# Compute the posterior predictions for the RV model
rv_pred = trace.posterior["rv_model_pred"].values
pred = np.percentile(rv_pred, [16, 50, 84], axis=(0, 1))
plt.plot(t, pred[1], color="C0", label="model")
art = plt.fill_between(t, pred[0], pred[2], color="C0", alpha=0.3)
art.set_edgecolor("none")
plt.legend(fontsize=10)
plt.xlim(t.min(), t.max())
plt.xlabel("time [days]")
plt.ylabel("radial velocity [m/s]")
_ = plt.title("posterior constraints")
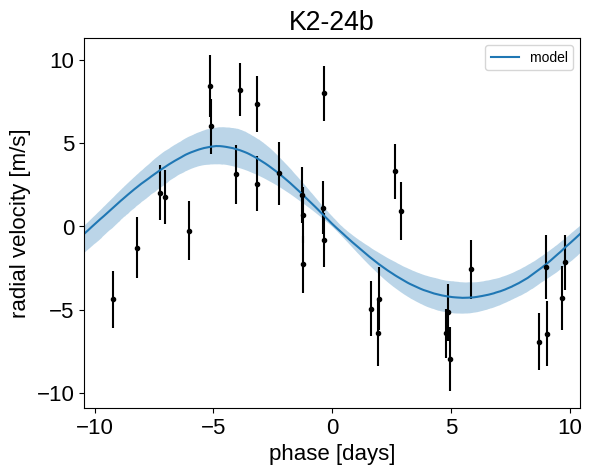
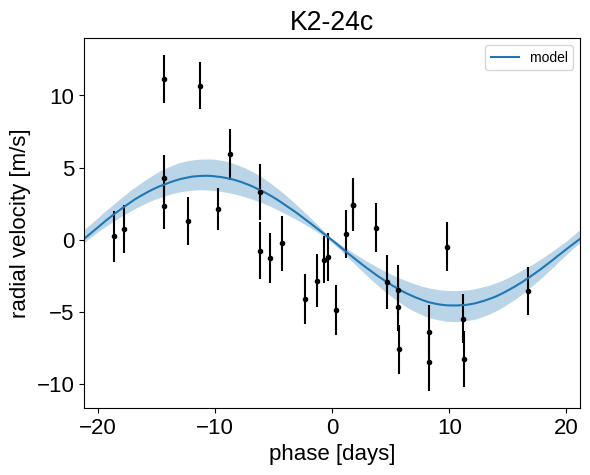
Phase plots#
It might be also be interesting to look at the phased plots for this system. Here we’ll fold the dataset on the median of posterior period and then overplot the posterior constraint on the folded model orbits.
for n, letter in enumerate("bc"):
plt.figure()
# Get the posterior median orbital parameters
p = np.median(trace.posterior["P"].values[:, :, n])
t0 = np.median(trace.posterior["t0"].values[:, :, n])
# Compute the median of posterior estimate of the background RV
# and the contribution from the other planet. Then we can remove
# this from the data to plot just the planet we care about.
other = np.median(
trace.posterior["vrad"].values[:, :, :, (n + 1) % 2], axis=(0, 1)
)
other += np.median(trace.posterior["bkg"].values, axis=(0, 1))
# Plot the folded data
x_fold = (x - t0 + 0.5 * p) % p - 0.5 * p
plt.errorbar(x_fold, y - other, yerr=yerr, fmt=".k")
# Compute the posterior prediction for the folded RV model for this
# planet
t_fold = (t - t0 + 0.5 * p) % p - 0.5 * p
inds = np.argsort(t_fold)
pred = np.percentile(
trace.posterior["vrad_pred"].values[:, :, inds, n],
[16, 50, 84],
axis=(0, 1),
)
plt.plot(t_fold[inds], pred[1], color="C0", label="model")
art = plt.fill_between(
t_fold[inds], pred[0], pred[2], color="C0", alpha=0.3
)
art.set_edgecolor("none")
plt.legend(fontsize=10)
plt.xlim(-0.5 * p, 0.5 * p)
plt.xlabel("phase [days]")
plt.ylabel("radial velocity [m/s]")
plt.title("K2-24{0}".format(letter))
Citations#
As described in the citation tutorial, we can use citations.get_citations_for_model to construct an acknowledgement and BibTeX listing that includes the relevant citations for this model.
with model:
txt, bib = xo.citations.get_citations_for_model()
print(txt)
This research made use of \textsf{exoplanet} \citep{exoplanet:joss,
exoplanet:zenodo} and its dependencies \citep{exoplanet:arviz,
exoplanet:astropy13, exoplanet:astropy18, exoplanet:pymc3, exoplanet:theano,
exoplanet:vaneylen19}.
print(bib.split("\n\n")[0] + "\n\n...")
@article{exoplanet:joss,
author = {{Foreman-Mackey}, Daniel and {Luger}, Rodrigo and {Agol}, Eric
and {Barclay}, Thomas and {Bouma}, Luke G. and {Brandt},
Timothy D. and {Czekala}, Ian and {David}, Trevor J. and
{Dong}, Jiayin and {Gilbert}, Emily A. and {Gordon}, Tyler A.
and {Hedges}, Christina and {Hey}, Daniel R. and {Morris},
Brett M. and {Price-Whelan}, Adrian M. and {Savel}, Arjun B.},
title = "{exoplanet: Gradient-based probabilistic inference for
exoplanet data \& other astronomical time series}",
journal = {arXiv e-prints},
year = 2021,
month = may,
eid = {arXiv:2105.01994},
pages = {arXiv:2105.01994},
archivePrefix = {arXiv},
eprint = {2105.01994},
primaryClass = {astro-ph.IM},
adsurl = {https://ui.adsabs.harvard.edu/abs/2021arXiv210501994F},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
...