Joint RV & transit fits#
import exoplanet
exoplanet.utils.docs_setup()
print(f"exoplanet.__version__ = '{exoplanet.__version__}'")
exoplanet.__version__ = '0.5.4.dev27+g75d7fcc'
In this tutorial, we will combine many of the previous tutorials to perform a fit of the K2-24 system using the K2 transit data and the RVs from Petigura et al. (2016). This is the same system that we fit in Radial velocity fitting and we’ll combine that model with the transit model from Transit fitting and the Gaussian Process noise model from Gaussian process models for stellar variability.
Datasets and initializations#
To get started, let’s download the relevant datasets. First, the transit light curve from Everest:
import numpy as np
import matplotlib.pyplot as plt
from astropy.io import fits
from scipy.signal import savgol_filter
# Download the data
lc_url = "https://archive.stsci.edu/hlsps/everest/v2/c02/203700000/71098/hlsp_everest_k2_llc_203771098-c02_kepler_v2.0_lc.fits"
with fits.open(lc_url) as hdus:
lc = hdus[1].data
lc_hdr = hdus[1].header
# Work out the exposure time
texp = lc_hdr["FRAMETIM"] * lc_hdr["NUM_FRM"]
texp /= 60.0 * 60.0 * 24.0
# Mask bad data
m = (
(np.arange(len(lc)) > 100)
& np.isfinite(lc["FLUX"])
& np.isfinite(lc["TIME"])
)
bad_bits = [1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 12, 13, 14, 16, 17]
qual = lc["QUALITY"]
for b in bad_bits:
m &= qual & 2 ** (b - 1) == 0
# Convert to parts per thousand
x = lc["TIME"][m]
y = lc["FLUX"][m]
mu = np.median(y)
y = (y / mu - 1) * 1e3
# Identify outliers
m = np.ones(len(y), dtype=bool)
for i in range(10):
y_prime = np.interp(x, x[m], y[m])
smooth = savgol_filter(y_prime, 101, polyorder=3)
resid = y - smooth
sigma = np.sqrt(np.mean(resid**2))
m0 = np.abs(resid) < 3 * sigma
if m.sum() == m0.sum():
m = m0
break
m = m0
# Only discard positive outliers
m = resid < 3 * sigma
# Shift the data so that the K2 data start at t=0. This tends to make the fit
# better behaved since t0 covaries with period.
x_ref = np.min(x[m])
x -= x_ref
# Plot the data
plt.plot(x, y, "k", label="data")
plt.plot(x, smooth)
plt.plot(x[~m], y[~m], "xr", label="outliers")
plt.legend(fontsize=12)
plt.xlim(x.min(), x.max())
plt.xlabel("time")
plt.ylabel("flux")
# Make sure that the data type is consistent
x = np.ascontiguousarray(x[m], dtype=np.float64)
y = np.ascontiguousarray(y[m], dtype=np.float64)
smooth = np.ascontiguousarray(smooth[m], dtype=np.float64)
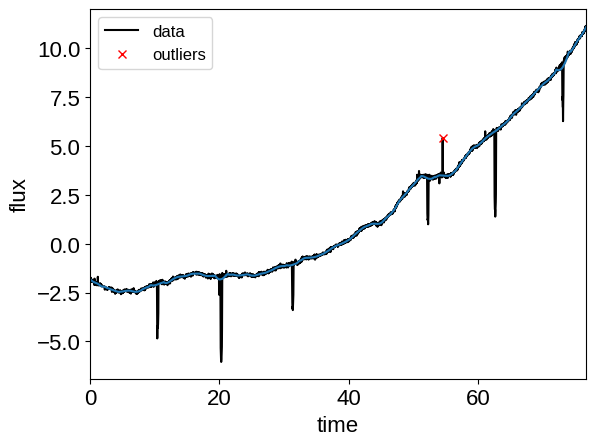
Then the RVs from RadVel:
import pandas as pd
url = "https://raw.githubusercontent.com/California-Planet-Search/radvel/master/example_data/epic203771098.csv"
data = pd.read_csv(url, index_col=0)
# Don't forget to remove the time offset from above!
x_rv = np.array(data.t) - x_ref
y_rv = np.array(data.vel)
yerr_rv = np.array(data.errvel)
plt.errorbar(x_rv, y_rv, yerr=yerr_rv, fmt=".k")
plt.xlabel("time [days]")
_ = plt.ylabel("radial velocity [m/s]")
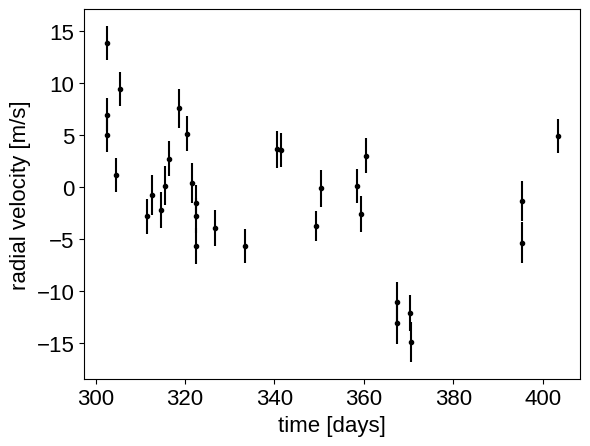
We can initialize the transit parameters using the box least squares periodogram from AstroPy. (Note: you’ll need AstroPy v3.1 or more recent to use this feature.) A full discussion of transit detection and vetting is beyond the scope of this tutorial so let’s assume that we know that there are two periodic transiting planets in this dataset.
from astropy.timeseries import BoxLeastSquares
m = np.zeros(len(x), dtype=bool)
period_grid = np.exp(np.linspace(np.log(5), np.log(50), 50000))
bls_results = []
periods = []
t0s = []
depths = []
# Compute the periodogram for each planet by iteratively masking out
# transits from the higher signal to noise planets. Here we're assuming
# that we know that there are exactly two planets.
for i in range(2):
bls = BoxLeastSquares(x[~m], y[~m] - smooth[~m])
bls_power = bls.power(period_grid, 0.1, oversample=20)
bls_results.append(bls_power)
# Save the highest peak as the planet candidate
index = np.argmax(bls_power.power)
periods.append(bls_power.period[index])
t0s.append(bls_power.transit_time[index])
depths.append(bls_power.depth[index])
# Mask the data points that are in transit for this candidate
m |= bls.transit_mask(x, periods[-1], 0.5, t0s[-1])
Let’s plot the initial transit estimates based on these periodograms:
fig, axes = plt.subplots(len(bls_results), 2, figsize=(15, 10))
for i in range(len(bls_results)):
# Plot the periodogram
ax = axes[i, 0]
ax.axvline(np.log10(periods[i]), color="C1", lw=5, alpha=0.8)
ax.plot(np.log10(bls_results[i].period), bls_results[i].power, "k")
ax.annotate(
"period = {0:.4f} d".format(periods[i]),
(0, 1),
xycoords="axes fraction",
xytext=(5, -5),
textcoords="offset points",
va="top",
ha="left",
fontsize=12,
)
ax.set_ylabel("bls power")
ax.set_yticks([])
ax.set_xlim(np.log10(period_grid.min()), np.log10(period_grid.max()))
if i < len(bls_results) - 1:
ax.set_xticklabels([])
else:
ax.set_xlabel("log10(period)")
# Plot the folded transit
ax = axes[i, 1]
p = periods[i]
x_fold = (x - t0s[i] + 0.5 * p) % p - 0.5 * p
m = np.abs(x_fold) < 0.4
ax.plot(x_fold[m], y[m] - smooth[m], ".k")
# Overplot the phase binned light curve
bins = np.linspace(-0.41, 0.41, 32)
denom, _ = np.histogram(x_fold, bins)
num, _ = np.histogram(x_fold, bins, weights=y - smooth)
denom[num == 0] = 1.0
ax.plot(0.5 * (bins[1:] + bins[:-1]), num / denom, color="C1")
ax.set_xlim(-0.4, 0.4)
ax.set_ylabel("relative flux [ppt]")
if i < len(bls_results) - 1:
ax.set_xticklabels([])
else:
ax.set_xlabel("time since transit")
_ = fig.subplots_adjust(hspace=0.02)
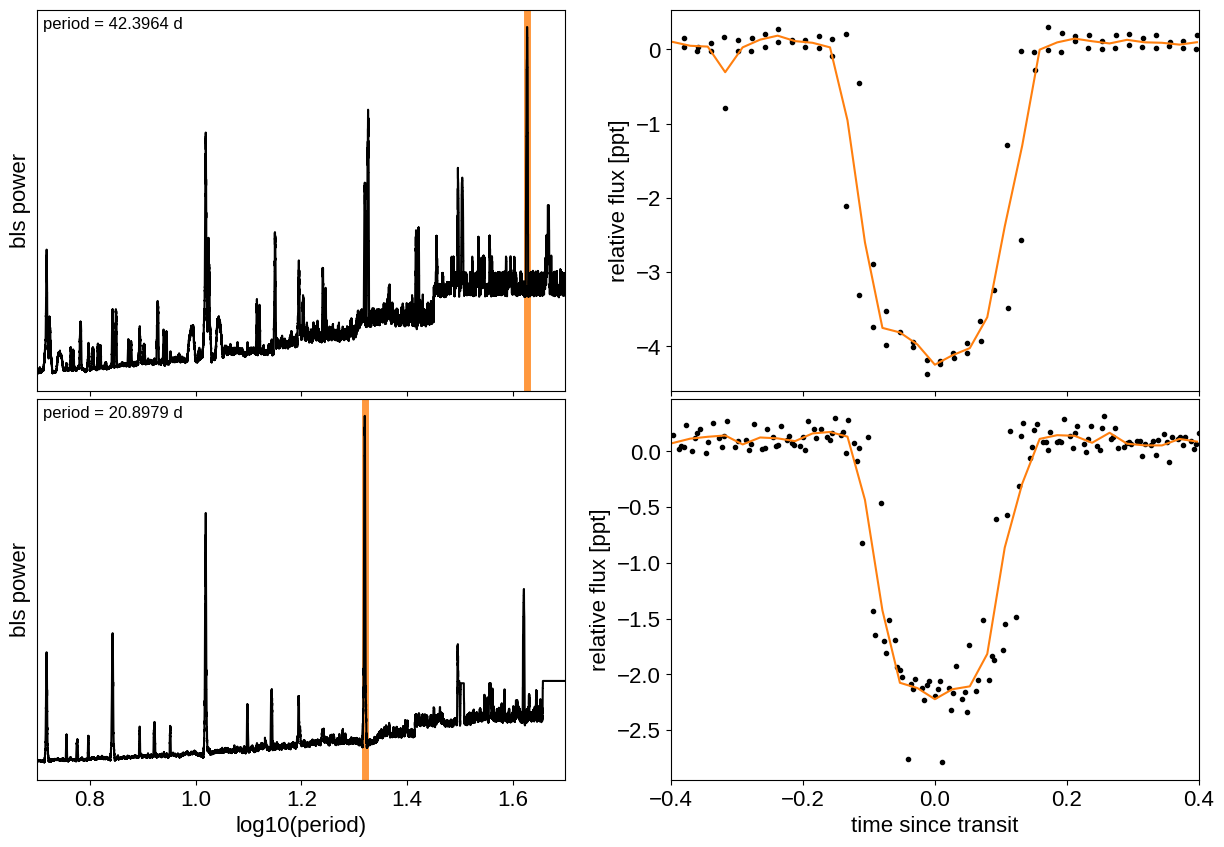
The discovery paper for K2-24 (Petigura et al. (2016)) includes the following estimates of the stellar mass and radius in Solar units:
M_star_petigura = 1.12, 0.05
R_star_petigura = 1.21, 0.11
Finally, using this stellar mass, we can also estimate the minimum masses of the planets given these transit parameters.
import exoplanet as xo
import astropy.units as u
msini = xo.estimate_minimum_mass(
periods, x_rv, y_rv, yerr_rv, t0s=t0s, m_star=M_star_petigura[0]
)
msini = msini.to(u.M_earth)
print(msini)
[32.79887948 23.87116183] earthMass
A joint transit and radial velocity model in PyMC3#
Now, let’s define our full model in PyMC3. There’s a lot going on here, but I’ve tried to comment it and most of it should be familiar from the other tutorials and case studies. In this case, I’ve put the model inside a model “factory” function because we’ll do some sigma clipping below.
import pymc3 as pm
import aesara_theano_fallback.tensor as tt
import pymc3_ext as pmx
from celerite2.theano import terms, GaussianProcess
# These arrays are used as the times/phases where the models are
# evaluated at higher resolution for plotting purposes
t_rv = np.linspace(x_rv.min() - 5, x_rv.max() + 5, 500)
phase_lc = np.linspace(-0.3, 0.3, 100)
def build_model(mask=None, start=None):
if mask is None:
mask = np.ones(len(x), dtype=bool)
with pm.Model() as model:
# Parameters for the stellar properties
mean_flux = pm.Normal("mean_flux", mu=0.0, sd=10.0)
u_star = xo.QuadLimbDark("u_star")
star = xo.LimbDarkLightCurve(u_star)
BoundedNormal = pm.Bound(pm.Normal, lower=0, upper=3)
m_star = BoundedNormal(
"m_star", mu=M_star_petigura[0], sd=M_star_petigura[1]
)
r_star = BoundedNormal(
"r_star", mu=R_star_petigura[0], sd=R_star_petigura[1]
)
# Orbital parameters for the planets
t0 = pm.Normal("t0", mu=np.array(t0s), sd=1, shape=2)
log_m_pl = pm.Normal("log_m_pl", mu=np.log(msini.value), sd=1, shape=2)
log_period = pm.Normal("log_period", mu=np.log(periods), sd=1, shape=2)
# Fit in terms of transit depth (assuming b<1)
b = pm.Uniform("b", lower=0, upper=1, shape=2)
log_depth = pm.Normal(
"log_depth", mu=np.log(depths), sigma=2.0, shape=2
)
ror = pm.Deterministic(
"ror",
star.get_ror_from_approx_transit_depth(
1e-3 * tt.exp(log_depth), b
),
)
r_pl = pm.Deterministic("r_pl", ror * r_star)
m_pl = pm.Deterministic("m_pl", tt.exp(log_m_pl))
period = pm.Deterministic("period", tt.exp(log_period))
ecs = pmx.UnitDisk("ecs", shape=(2, 2), testval=0.01 * np.ones((2, 2)))
ecc = pm.Deterministic("ecc", tt.sum(ecs**2, axis=0))
omega = pm.Deterministic("omega", tt.arctan2(ecs[1], ecs[0]))
xo.eccentricity.vaneylen19(
"ecc_prior", multi=True, shape=2, fixed=True, observed=ecc
)
# RV jitter & a quadratic RV trend
log_sigma_rv = pm.Normal(
"log_sigma_rv", mu=np.log(np.median(yerr_rv)), sd=5
)
trend = pm.Normal(
"trend", mu=0, sd=10.0 ** -np.arange(3)[::-1], shape=3
)
# Transit jitter & GP parameters
log_sigma_lc = pm.Normal(
"log_sigma_lc", mu=np.log(np.std(y[mask])), sd=10
)
log_rho_gp = pm.Normal("log_rho_gp", mu=0.0, sd=10)
log_sigma_gp = pm.Normal(
"log_sigma_gp", mu=np.log(np.std(y[mask])), sd=10
)
# Orbit models
orbit = xo.orbits.KeplerianOrbit(
r_star=r_star,
m_star=m_star,
period=period,
t0=t0,
b=b,
m_planet=xo.units.with_unit(m_pl, msini.unit),
ecc=ecc,
omega=omega,
)
# Compute the model light curve
light_curves = (
star.get_light_curve(orbit=orbit, r=r_pl, t=x[mask], texp=texp)
* 1e3
)
light_curve = pm.math.sum(light_curves, axis=-1) + mean_flux
resid = y[mask] - light_curve
# GP model for the light curve
kernel = terms.SHOTerm(
sigma=tt.exp(log_sigma_gp),
rho=tt.exp(log_rho_gp),
Q=1 / np.sqrt(2),
)
gp = GaussianProcess(kernel, t=x[mask], yerr=tt.exp(log_sigma_lc))
gp.marginal("transit_obs", observed=resid)
# And then include the RVs as in the RV tutorial
x_rv_ref = 0.5 * (x_rv.min() + x_rv.max())
def get_rv_model(t, name=""):
# First the RVs induced by the planets
vrad = orbit.get_radial_velocity(t)
pm.Deterministic("vrad" + name, vrad)
# Define the background model
A = np.vander(t - x_rv_ref, 3)
bkg = pm.Deterministic("bkg" + name, tt.dot(A, trend))
# Sum over planets and add the background to get the full model
return pm.Deterministic(
"rv_model" + name, tt.sum(vrad, axis=-1) + bkg
)
# Define the model
rv_model = get_rv_model(x_rv)
get_rv_model(t_rv, name="_pred")
# The likelihood for the RVs
err = tt.sqrt(yerr_rv**2 + tt.exp(2 * log_sigma_rv))
pm.Normal("obs", mu=rv_model, sd=err, observed=y_rv)
# Compute and save the phased light curve models
pm.Deterministic(
"lc_pred",
1e3
* tt.stack(
[
star.get_light_curve(
orbit=orbit, r=r_pl, t=t0[n] + phase_lc, texp=texp
)[..., n]
for n in range(2)
],
axis=-1,
),
)
# Fit for the maximum a posteriori parameters, I've found that I can get
# a better solution by trying different combinations of parameters in turn
if start is None:
start = model.test_point
map_soln = pmx.optimize(start=start, vars=[trend])
map_soln = pmx.optimize(start=map_soln, vars=[log_sigma_lc])
map_soln = pmx.optimize(start=map_soln, vars=[log_depth, b])
map_soln = pmx.optimize(start=map_soln, vars=[log_period, t0])
map_soln = pmx.optimize(
start=map_soln, vars=[log_sigma_lc, log_sigma_gp]
)
map_soln = pmx.optimize(start=map_soln, vars=[log_rho_gp])
map_soln = pmx.optimize(start=map_soln)
extras = dict(
zip(
["light_curves", "gp_pred"],
pmx.eval_in_model([light_curves, gp.predict(resid)], map_soln),
)
)
return model, map_soln, extras
model0, map_soln0, extras0 = build_model()
optimizing logp for variables: [trend]
message: Optimization terminated successfully.
logp: -8631.825236572244 -> -8618.748246268859
optimizing logp for variables: [log_sigma_lc]
message: Optimization terminated successfully.
logp: -8618.748246268859 -> 597.2641171918347
optimizing logp for variables: [b, log_depth]
message: Optimization terminated successfully.
logp: 597.2641171918347 -> 695.1630815828709
optimizing logp for variables: [t0, log_period]
message: Optimization terminated successfully.
logp: 695.1630815828745 -> 761.6475166691648
optimizing logp for variables: [log_sigma_gp, log_sigma_lc]
message: Optimization terminated successfully.
logp: 761.6475166691723 -> 1452.7201459533062
optimizing logp for variables: [log_rho_gp]
message: Desired error not necessarily achieved due to precision loss.
logp: 1452.7201459533062 -> 1809.494299009002
optimizing logp for variables: [log_sigma_gp, log_rho_gp, log_sigma_lc, trend, log_sigma_rv, ecs, log_depth, b, log_period, log_m_pl, t0, r_star, m_star, u_star, mean_flux]
message: Desired error not necessarily achieved due to precision loss.
logp: 1809.4942990089928 -> 4736.759862400065
Now let’s plot the map radial velocity model.
def plot_rv_curve(soln):
fig, axes = plt.subplots(2, 1, figsize=(10, 5), sharex=True)
ax = axes[0]
ax.errorbar(x_rv, y_rv, yerr=yerr_rv, fmt=".k")
ax.plot(t_rv, soln["vrad_pred"], "--k", alpha=0.5)
ax.plot(t_rv, soln["bkg_pred"], ":k", alpha=0.5)
ax.plot(t_rv, soln["rv_model_pred"], label="model")
ax.legend(fontsize=10)
ax.set_ylabel("radial velocity [m/s]")
ax = axes[1]
err = np.sqrt(yerr_rv**2 + np.exp(2 * soln["log_sigma_rv"]))
ax.errorbar(x_rv, y_rv - soln["rv_model"], yerr=err, fmt=".k")
ax.axhline(0, color="k", lw=1)
ax.set_ylabel("residuals [m/s]")
ax.set_xlim(t_rv.min(), t_rv.max())
ax.set_xlabel("time [days]")
_ = plot_rv_curve(map_soln0)
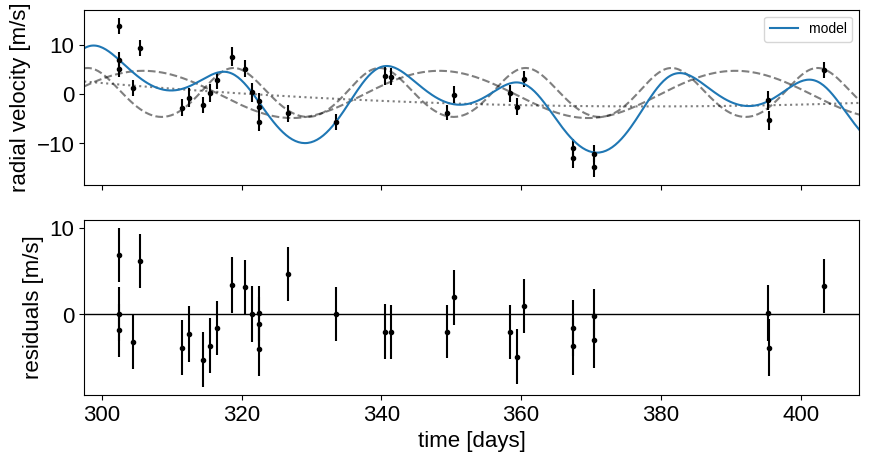
That looks pretty similar to what we got in Radial velocity fitting. Now let’s also plot the transit model.
def plot_light_curve(soln, extras, mask=None):
if mask is None:
mask = np.ones(len(x), dtype=bool)
fig, axes = plt.subplots(3, 1, figsize=(10, 7), sharex=True)
ax = axes[0]
ax.plot(x[mask], y[mask], "k", label="data")
gp_mod = extras["gp_pred"] + soln["mean_flux"]
ax.plot(x[mask], gp_mod, color="C2", label="gp model")
ax.legend(fontsize=10)
ax.set_ylabel("relative flux [ppt]")
ax = axes[1]
ax.plot(x[mask], y[mask] - gp_mod, "k", label="de-trended data")
for i, l in enumerate("bc"):
mod = extras["light_curves"][:, i]
ax.plot(x[mask], mod, label="planet {0}".format(l))
ax.legend(fontsize=10, loc=3)
ax.set_ylabel("de-trended flux [ppt]")
ax = axes[2]
mod = gp_mod + np.sum(extras["light_curves"], axis=-1)
ax.plot(x[mask], y[mask] - mod, "k")
ax.axhline(0, color="#aaaaaa", lw=1)
ax.set_ylabel("residuals [ppt]")
ax.set_xlim(x[mask].min(), x[mask].max())
ax.set_xlabel("time [days]")
return fig
_ = plot_light_curve(map_soln0, extras0)
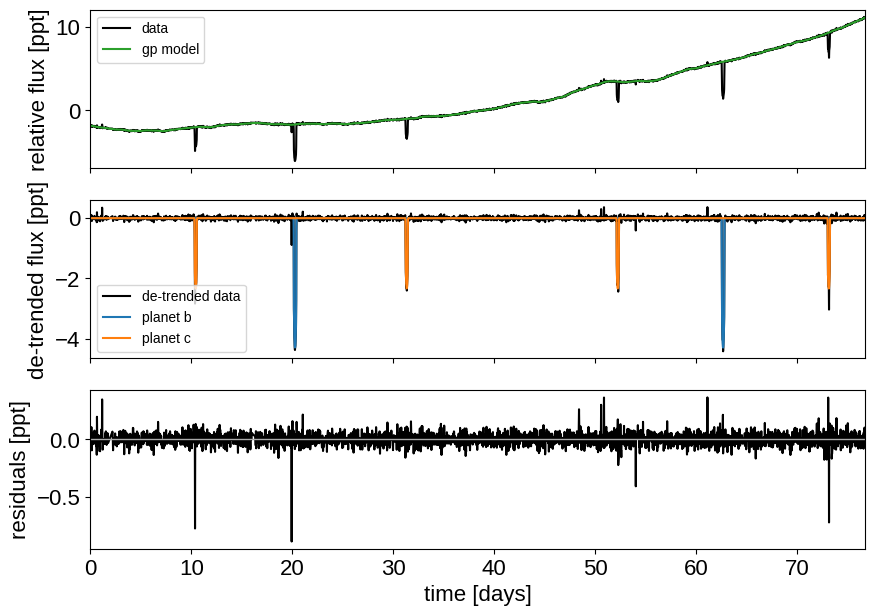
There are still a few outliers in the light curve and it can be useful to remove those before doing the full fit because both the GP and transit parameters can be sensitive to this.
Sigma clipping#
To remove the outliers, we’ll look at the empirical RMS of the residuals away from the GP + transit model and remove anything that is more than a 7-sigma outlier.
mod = (
extras0["gp_pred"]
+ map_soln0["mean_flux"]
+ np.sum(extras0["light_curves"], axis=-1)
)
resid = y - mod
rms = np.sqrt(np.median(resid**2))
mask = np.abs(resid) < 7 * rms
plt.plot(x, resid, "k", label="data")
plt.plot(x[~mask], resid[~mask], "xr", label="outliers")
plt.axhline(0, color="#aaaaaa", lw=1)
plt.ylabel("residuals [ppt]")
plt.xlabel("time [days]")
plt.legend(fontsize=12, loc=4)
_ = plt.xlim(x.min(), x.max())
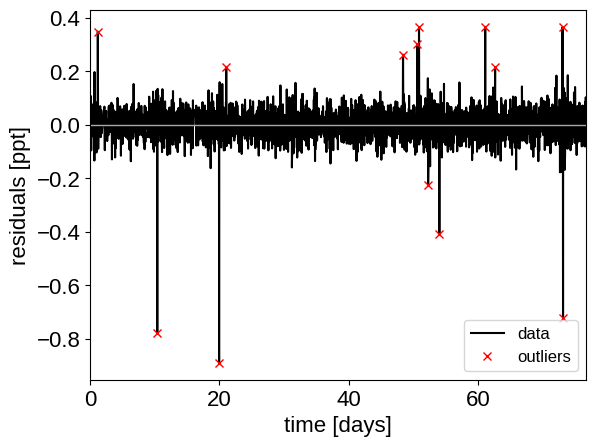
That looks better. Let’s re-build our model with this sigma-clipped dataset.
model, map_soln, extras = build_model(mask, map_soln0)
_ = plot_light_curve(map_soln, extras, mask)
optimizing logp for variables: [trend]
message: Optimization terminated successfully.
logp: 5186.334119926878 -> 5186.334119926878
optimizing logp for variables: [log_sigma_lc]
message: Optimization terminated successfully.
logp: 5186.334119926878 -> 5268.2491175829855
optimizing logp for variables: [b, log_depth]
message: Optimization terminated successfully.
logp: 5268.2491175829855 -> 5279.212605462046
optimizing logp for variables: [t0, log_period]
message: Desired error not necessarily achieved due to precision loss.
logp: 5279.212605462044 -> 5280.6950399098105
optimizing logp for variables: [log_sigma_gp, log_sigma_lc]
message: Optimization terminated successfully.
logp: 5280.695039909809 -> 5281.428174122519
optimizing logp for variables: [log_rho_gp]
message: Optimization terminated successfully.
logp: 5281.428174122519 -> 5281.429435936685
optimizing logp for variables: [log_sigma_gp, log_rho_gp, log_sigma_lc, trend, log_sigma_rv, ecs, log_depth, b, log_period, log_m_pl, t0, r_star, m_star, u_star, mean_flux]
message: Desired error not necessarily achieved due to precision loss.
logp: 5281.429435936686 -> 5282.933651598012
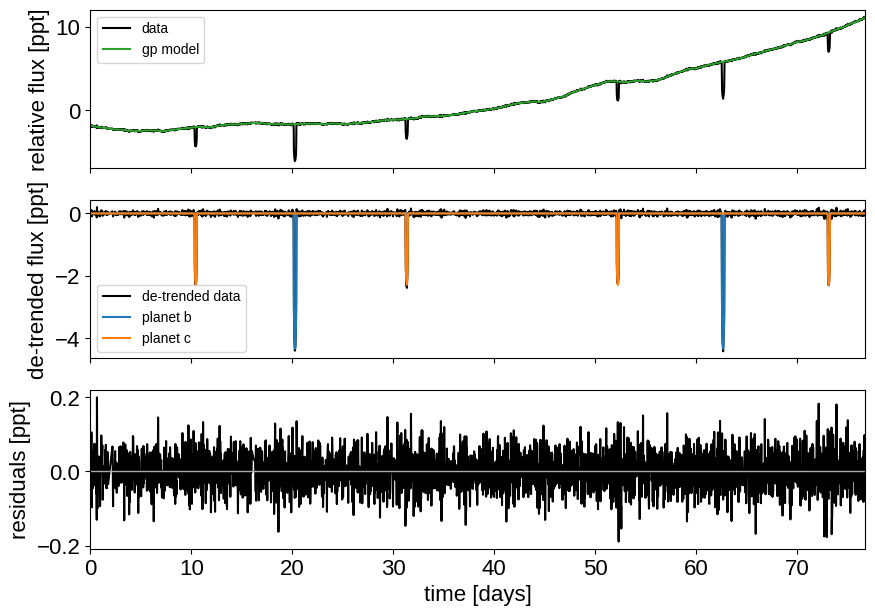
Great! Now we’re ready to sample.
Sampling#
The sampling for this model is the same as for all the previous tutorials, but it takes a bit longer. This is partly because the model is more expensive to compute than the previous ones and partly because there are some non-affine degeneracies in the problem (for example between impact parameter, eccentricity, and radius/radius ratio). It might be worth thinking about reparameterizations (in terms of duration instead of eccentricity), but that’s beyond the scope of this tutorial. Besides, using more traditional MCMC methods, this would have taken a lot longer to get thousands of effective samples!
import multiprocessing
with model:
trace = pm.sample(
tune=1500,
draws=1000,
start=map_soln,
cores=2,
chains=2,
target_accept=0.95,
return_inferencedata=True,
random_seed=[203771098, 203775000],
mp_ctx=multiprocessing.get_context("fork"),
init="adapt_full",
)
Auto-assigning NUTS sampler...
Initializing NUTS using adapt_full...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [log_sigma_gp, log_rho_gp, log_sigma_lc, trend, log_sigma_rv, ecs, log_depth, b, log_period, log_m_pl, t0, r_star, m_star, u_star, mean_flux]
Sampling 2 chains for 1_500 tune and 1_000 draw iterations (3_000 + 2_000 draws total) took 432 seconds.
The number of effective samples is smaller than 25% for some parameters.
Let’s look at the convergence diagnostics for some of the key parameters:
import arviz as az
az.summary(
trace,
var_names=[
"period",
"r_pl",
"m_pl",
"ecc",
"omega",
"b",
"log_sigma_gp",
"log_rho_gp",
],
)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| period[0] | 42.363 | 0.000 | 42.363 | 42.364 | 0.000 | 0.000 | 2178.0 | 1688.0 | 1.0 |
| period[1] | 20.885 | 0.000 | 20.885 | 20.886 | 0.000 | 0.000 | 2231.0 | 1608.0 | 1.0 |
| r_pl[0] | 0.078 | 0.004 | 0.069 | 0.085 | 0.000 | 0.000 | 397.0 | 350.0 | 1.0 |
| r_pl[1] | 0.056 | 0.003 | 0.049 | 0.062 | 0.000 | 0.000 | 324.0 | 274.0 | 1.0 |
| m_pl[0] | 27.082 | 6.034 | 16.212 | 38.441 | 0.162 | 0.114 | 1394.0 | 764.0 | 1.0 |
| m_pl[1] | 21.938 | 4.534 | 12.596 | 29.603 | 0.116 | 0.082 | 1565.0 | 848.0 | 1.0 |
| ecc[0] | 0.037 | 0.029 | 0.000 | 0.085 | 0.001 | 0.001 | 890.0 | 883.0 | 1.0 |
| ecc[1] | 0.091 | 0.084 | 0.000 | 0.265 | 0.004 | 0.003 | 674.0 | 1193.0 | 1.0 |
| omega[0] | 0.230 | 1.999 | -2.948 | 3.076 | 0.074 | 0.052 | 950.0 | 1543.0 | 1.0 |
| omega[1] | -0.408 | 1.039 | -2.636 | 1.617 | 0.036 | 0.025 | 837.0 | 1457.0 | 1.0 |
| b[0] | 0.590 | 0.045 | 0.499 | 0.661 | 0.002 | 0.001 | 662.0 | 701.0 | 1.0 |
| b[1] | 0.535 | 0.105 | 0.333 | 0.710 | 0.007 | 0.005 | 293.0 | 166.0 | 1.0 |
| log_sigma_gp | 2.153 | 0.610 | 1.172 | 3.269 | 0.022 | 0.017 | 982.0 | 719.0 | 1.0 |
| log_rho_gp | 4.547 | 0.414 | 3.928 | 5.364 | 0.015 | 0.011 | 980.0 | 749.0 | 1.0 |
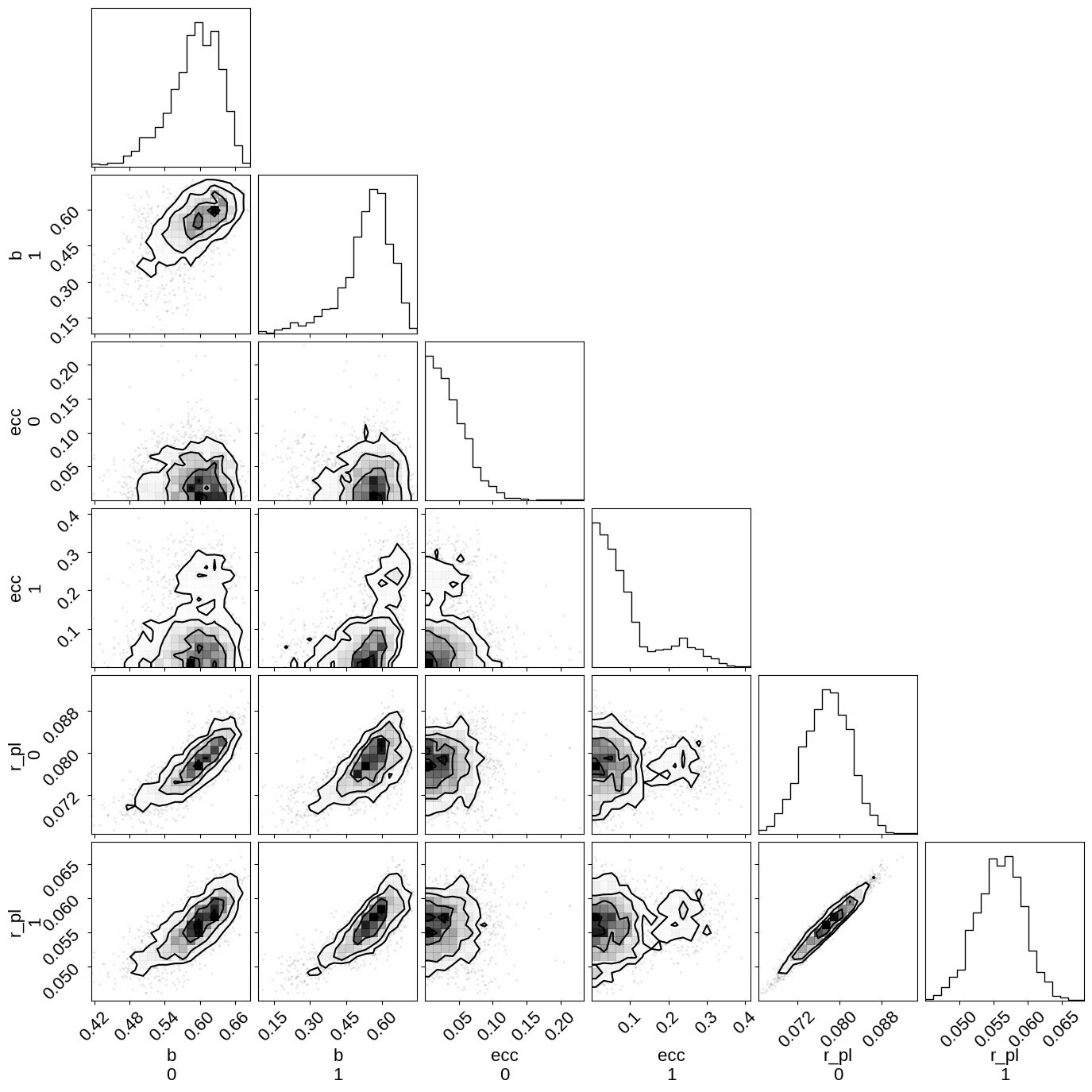
As you see, the effective number of samples for the impact parameters and eccentricites are lower than for the other parameters. This is because of the correlations that I mentioned above:
import corner
_ = corner.corner(trace, var_names=["b", "ecc", "r_pl"])
Phase plots#
Finally, we can make folded plots of the transits and the radial velocities and compare to the posterior model predictions. (Note: planets b and c in this tutorial are swapped compared to the labels from Petigura et al. (2016))
flat_samps = trace.posterior.stack(sample=("chain", "draw"))
gp_mod = extras["gp_pred"] + map_soln["mean_flux"]
for n, letter in enumerate("bc"):
plt.figure()
# Get the posterior median orbital parameters
p = np.median(flat_samps["period"][n])
t0 = np.median(flat_samps["t0"][n])
# Plot the folded data
x_fold = (x[mask] - t0 + 0.5 * p) % p - 0.5 * p
m = np.abs(x_fold) < 0.3
plt.plot(
x_fold[m], y[mask][m] - gp_mod[m], ".k", label="data", zorder=-1000
)
# Plot the folded model
pred = np.percentile(flat_samps["lc_pred"][:, n, :], [16, 50, 84], axis=-1)
plt.plot(phase_lc, pred[1], color="C1", label="model")
art = plt.fill_between(
phase_lc, pred[0], pred[2], color="C1", alpha=0.5, zorder=1000
)
art.set_edgecolor("none")
# Annotate the plot with the planet's period
txt = "period = {0:.4f} +/- {1:.4f} d".format(
np.mean(flat_samps["period"][n].values),
np.std(flat_samps["period"][n].values),
)
plt.annotate(
txt,
(0, 0),
xycoords="axes fraction",
xytext=(5, 5),
textcoords="offset points",
ha="left",
va="bottom",
fontsize=12,
)
plt.legend(fontsize=10, loc=4)
plt.xlabel("time since transit [days]")
plt.ylabel("de-trended flux")
plt.title("K2-24{0}".format(letter))
plt.xlim(-0.3, 0.3)
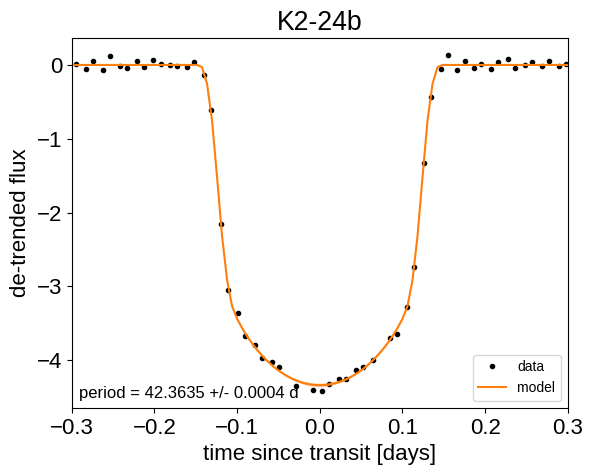
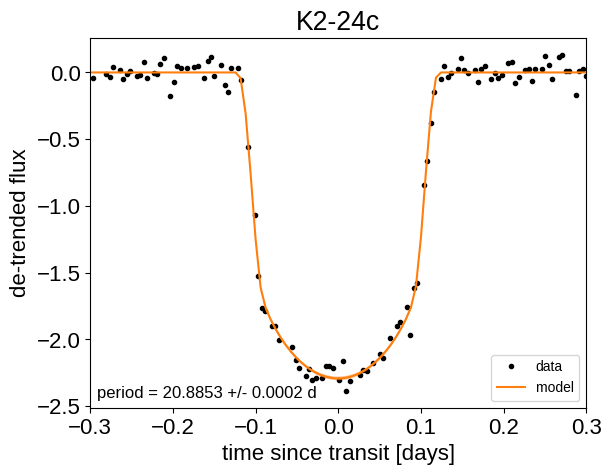
for n, letter in enumerate("bc"):
plt.figure()
# Get the posterior median orbital parameters
p = np.median(flat_samps["period"][n])
t0 = np.median(flat_samps["t0"][n])
# Compute the median of posterior estimate of the background RV
# and the contribution from the other planet. Then we can remove
# this from the data to plot just the planet we care about.
other = np.median(flat_samps["vrad"][:, (n + 1) % 2], axis=-1)
other += np.median(flat_samps["bkg"], axis=-1)
# Plot the folded data
x_fold = (x_rv - t0 + 0.5 * p) % p - 0.5 * p
plt.errorbar(x_fold, y_rv - other, yerr=yerr_rv, fmt=".k", label="data")
# Compute the posterior prediction for the folded RV model for this
# planet
t_fold = (t_rv - t0 + 0.5 * p) % p - 0.5 * p
inds = np.argsort(t_fold)
pred = np.percentile(
flat_samps["vrad_pred"][inds, n], [16, 50, 84], axis=-1
)
plt.plot(t_fold[inds], pred[1], color="C1", label="model")
art = plt.fill_between(
t_fold[inds], pred[0], pred[2], color="C1", alpha=0.3
)
art.set_edgecolor("none")
plt.legend(fontsize=10)
plt.xlim(-0.5 * p, 0.5 * p)
plt.xlabel("phase [days]")
plt.ylabel("radial velocity [m/s]")
plt.title("K2-24{0}".format(letter))
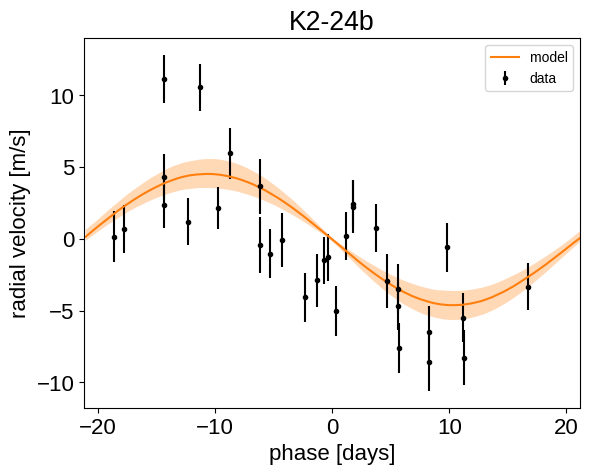
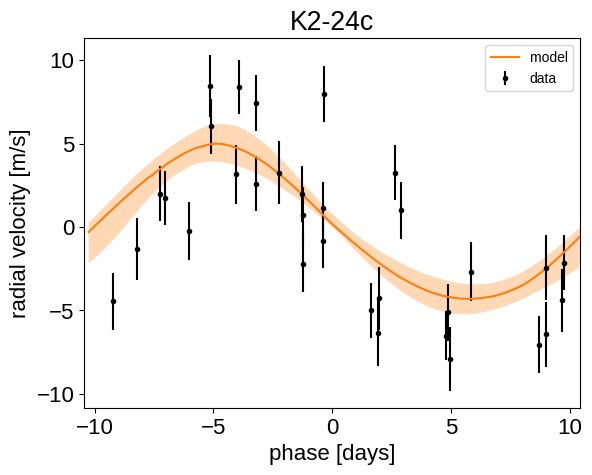
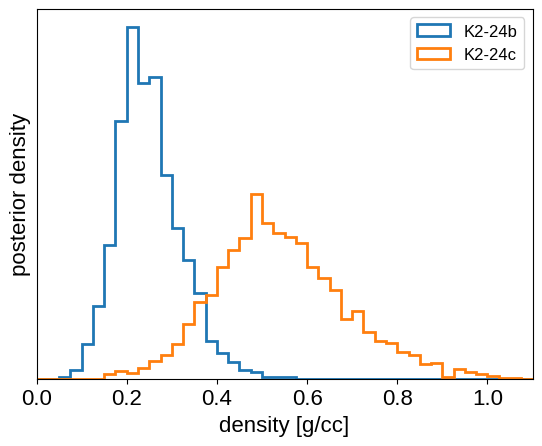
We can also compute the posterior constraints on the planet densities.
volume = 4 / 3 * np.pi * flat_samps["r_pl"].values ** 3
density = u.Quantity(
flat_samps["m_pl"].values / volume, unit=u.M_earth / u.R_sun**3
)
density = density.to(u.g / u.cm**3).value
bins = np.linspace(0, 1.1, 45)
for n, letter in enumerate("bc"):
plt.hist(
density[n],
bins,
histtype="step",
lw=2,
label="K2-24{0}".format(letter),
density=True,
)
plt.yticks([])
plt.legend(fontsize=12)
plt.xlim(bins[0], bins[-1])
plt.xlabel("density [g/cc]")
_ = plt.ylabel("posterior density")
Citations#
As described in the citation tutorial, we can use citations.get_citations_for_model to construct an acknowledgement and BibTeX listing that includes the relevant citations for this model.
with model:
txt, bib = xo.citations.get_citations_for_model()
print(txt)
This research made use of \textsf{exoplanet} \citep{exoplanet:joss,
exoplanet:zenodo} and its dependencies \citep{celerite2:foremanmackey17,
celerite2:foremanmackey18, exoplanet:agol20, exoplanet:arviz,
exoplanet:astropy13, exoplanet:astropy18, exoplanet:kipping13,
exoplanet:luger18, exoplanet:pymc3, exoplanet:theano, exoplanet:vaneylen19}.
print(bib.split("\n\n")[0] + "\n\n...")
@article{exoplanet:joss,
author = {{Foreman-Mackey}, Daniel and {Luger}, Rodrigo and {Agol}, Eric
and {Barclay}, Thomas and {Bouma}, Luke G. and {Brandt},
Timothy D. and {Czekala}, Ian and {David}, Trevor J. and
{Dong}, Jiayin and {Gilbert}, Emily A. and {Gordon}, Tyler A.
and {Hedges}, Christina and {Hey}, Daniel R. and {Morris},
Brett M. and {Price-Whelan}, Adrian M. and {Savel}, Arjun B.},
title = "{exoplanet: Gradient-based probabilistic inference for
exoplanet data \& other astronomical time series}",
journal = {arXiv e-prints},
year = 2021,
month = may,
eid = {arXiv:2105.01994},
pages = {arXiv:2105.01994},
archivePrefix = {arXiv},
eprint = {2105.01994},
primaryClass = {astro-ph.IM},
adsurl = {https://ui.adsabs.harvard.edu/abs/2021arXiv210501994F},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
...