Quick fits for TESS light curves#
import exoplanet
exoplanet.utils.docs_setup()
print(f"exoplanet.__version__ = '{exoplanet.__version__}'")
exoplanet.__version__ = '0.5.4.dev27+g75d7fcc'
In this tutorial, we will fit the TESS light curve for a known transiting planet. While the Fitting TESS data case study goes through the full details of an end-to-end fit, this tutorial is significantly faster to run and it can give pretty excellent results depending on your goals. Some of the main differences are:
We start from the light curve rather than doing the photometry ourselves. This should pretty much always be fine unless you have a very bright, faint, or crowded target.
We assume a circular orbit, but as you’ll see later, we can approximately relax this assumption later.
We only fit the data near transit. In many cases this will be just fine, but if you have predictable stellar variability (like coherent rotation) then you might do better fitting more data.
We’ll fit the planet in the HD 118203 (TIC 286923464) system that was found to transit by Pepper et al. (2019) because it is on an eccentric orbit so assumption #2 above is not valid.
First, let’s download the TESS light curve using lightkurve:
import numpy as np
import lightkurve as lk
import matplotlib.pyplot as plt
lcfs = lk.search_lightcurve(
"TIC 286923464", mission="TESS", author="SPOC"
).download_all(flux_column="pdcsap_flux")
lc = lcfs.stitch().remove_nans().remove_outliers(sigma=7)
x = np.ascontiguousarray(lc.time.value, dtype=np.float64)
y = np.ascontiguousarray(1e3 * (lc.flux - 1), dtype=np.float64)
yerr = np.ascontiguousarray(1e3 * lc.flux_err, dtype=np.float64)
texp = np.min(np.diff(x))
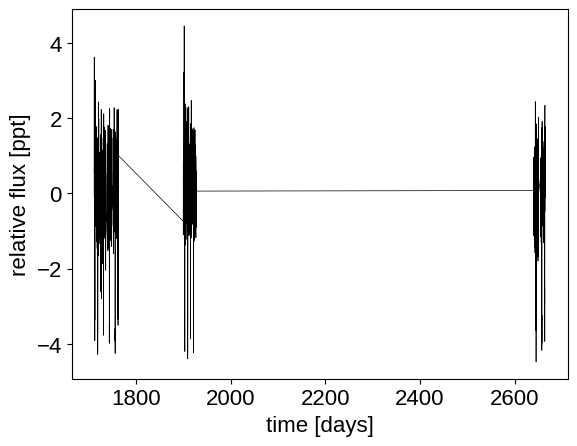
plt.plot(x, y, "k", linewidth=0.5)
plt.xlabel("time [days]")
_ = plt.ylabel("relative flux [ppt]")
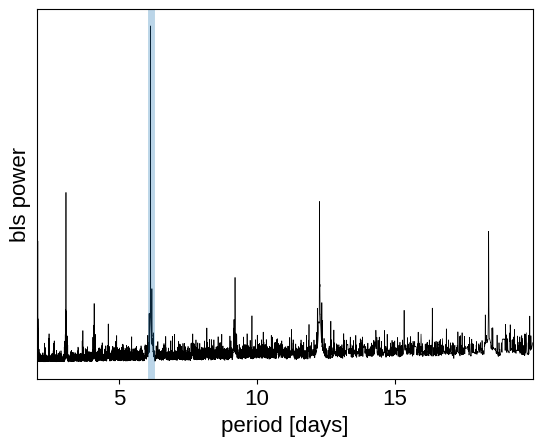
Then, find the period, phase and depth of the transit using box least squares:stitch
import exoplanet as xo
pg = xo.estimators.bls_estimator(x, y, yerr, min_period=2, max_period=20)
peak = pg["peak_info"]
period_guess = peak["period"]
t0_guess = peak["transit_time"]
depth_guess = peak["depth"]
plt.plot(pg["bls"].period, pg["bls"].power, "k", linewidth=0.5)
plt.axvline(period_guess, alpha=0.3, linewidth=5)
plt.xlabel("period [days]")
plt.ylabel("bls power")
plt.yticks([])
_ = plt.xlim(pg["bls"].period.min(), pg["bls"].period.max())
Then, for efficiency purposes, let’s extract just the data within 0.25 days of the transits:
transit_mask = (
np.abs(
(x - t0_guess + 0.5 * period_guess) % period_guess - 0.5 * period_guess
)
< 0.25
)
x = np.ascontiguousarray(x[transit_mask])
y = np.ascontiguousarray(y[transit_mask])
yerr = np.ascontiguousarray(yerr[transit_mask])
plt.figure(figsize=(8, 4))
x_fold = (
x - t0_guess + 0.5 * period_guess
) % period_guess - 0.5 * period_guess
plt.scatter(x_fold, y, c=x, s=3)
plt.xlabel("time since transit [days]")
plt.ylabel("relative flux [ppt]")
plt.colorbar(label="time [days]")
_ = plt.xlim(-0.25, 0.25)
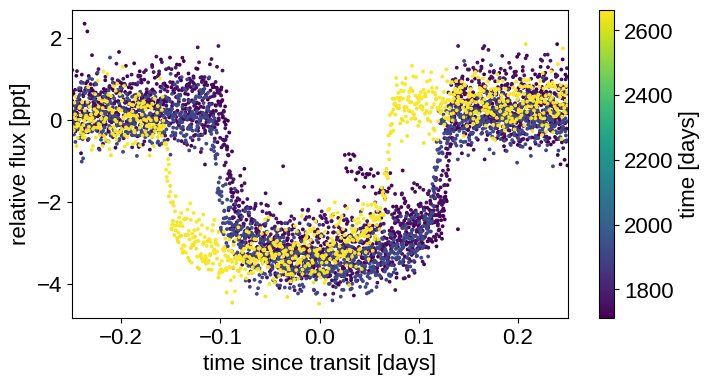
That looks a little janky, but it’s good enough for now.
The probabilistic model#
Here’s how we set up the PyMC3 model in this case:
import pymc3 as pm
import aesara_theano_fallback.tensor as tt
import pymc3_ext as pmx
from celerite2.theano import terms, GaussianProcess
with pm.Model() as model:
# Stellar parameters
mean = pm.Normal("mean", mu=0.0, sigma=10.0)
u = xo.QuadLimbDark("u")
star_params = [mean, u]
# Gaussian process noise model
sigma = pm.InverseGamma("sigma", alpha=3.0, beta=2 * np.median(yerr))
log_sigma_gp = pm.Normal("log_sigma_gp", mu=0.0, sigma=10.0)
log_rho_gp = pm.Normal("log_rho_gp", mu=np.log(10.0), sigma=10.0)
kernel = terms.SHOTerm(
sigma=tt.exp(log_sigma_gp), rho=tt.exp(log_rho_gp), Q=1.0 / 3
)
noise_params = [sigma, log_sigma_gp, log_rho_gp]
# Planet parameters
log_ror = pm.Normal(
"log_ror", mu=0.5 * np.log(depth_guess * 1e-3), sigma=10.0
)
ror = pm.Deterministic("ror", tt.exp(log_ror))
# Orbital parameters
log_period = pm.Normal("log_period", mu=np.log(period_guess), sigma=1.0)
period = pm.Deterministic("period", tt.exp(log_period))
t0 = pm.Normal("t0", mu=t0_guess, sigma=1.0)
log_dur = pm.Normal("log_dur", mu=np.log(0.1), sigma=10.0)
dur = pm.Deterministic("dur", tt.exp(log_dur))
b = xo.distributions.ImpactParameter("b", ror=ror)
# Set up the orbit
orbit = xo.orbits.KeplerianOrbit(period=period, duration=dur, t0=t0, b=b)
# We're going to track the implied density for reasons that will become clear later
pm.Deterministic("rho_circ", orbit.rho_star)
# Set up the mean transit model
star = xo.LimbDarkLightCurve(u)
lc_model = mean + 1e3 * tt.sum(
star.get_light_curve(orbit=orbit, r=ror, t=x), axis=-1
)
# Finally the GP observation model
gp = GaussianProcess(kernel, t=x, diag=yerr**2 + sigma**2)
gp.marginal("obs", observed=y - lc_model)
# Double check that everything looks good - we shouldn't see any NaNs!
print(model.check_test_point())
# Optimize the model
map_soln = model.test_point
map_soln = pmx.optimize(map_soln, [sigma])
map_soln = pmx.optimize(map_soln, [ror, b, dur])
map_soln = pmx.optimize(map_soln, noise_params)
map_soln = pmx.optimize(map_soln, star_params)
map_soln = pmx.optimize(map_soln)
mean -3.22
u_quadlimbdark__ -2.77
sigma_log__ -0.53
log_sigma_gp -3.22
log_rho_gp -3.22
log_ror -3.22
log_period -0.92
t0 -0.92
log_dur -3.22
b_impact__ -1.39
obs -34364.49
Name: Log-probability of test_point, dtype: float64
optimizing logp for variables: [sigma]
message: Optimization terminated successfully.
logp: -34387.13404363601 -> -8213.215637097146
optimizing logp for variables: [log_dur, b, log_ror]
message: Optimization terminated successfully.
logp: -8213.215637097146 -> -6545.214222425454
optimizing logp for variables: [log_rho_gp, log_sigma_gp, sigma]
message: Optimization terminated successfully.
logp: -6545.214222425454 -> -2398.0908102957096
optimizing logp for variables: [u, mean]
message: Optimization terminated successfully.
logp: -2398.0908102957096 -> -2393.9168049152004
optimizing logp for variables: [b, log_dur, t0, log_period, log_ror, log_rho_gp, log_sigma_gp, sigma, u, mean]
message: Desired error not necessarily achieved due to precision loss.
logp: -2393.9168049152004 -> -1841.6470841125888
Now we can plot our initial model:
with model:
lc_pred = pmx.eval_in_model(lc_model, map_soln)
gp_pred = pmx.eval_in_model(gp.predict(y - lc_pred), map_soln)
plt.figure(figsize=(8, 4))
x_fold = (x - map_soln["t0"] + 0.5 * map_soln["period"]) % map_soln[
"period"
] - 0.5 * map_soln["period"]
inds = np.argsort(x_fold)
plt.scatter(x_fold, y - gp_pred - map_soln["mean"], c=x, s=3)
plt.plot(x_fold[inds], lc_pred[inds] - map_soln["mean"], "k")
plt.xlabel("time since transit [days]")
plt.ylabel("relative flux [ppt]")
plt.colorbar(label="time [days]")
_ = plt.xlim(-0.25, 0.25)
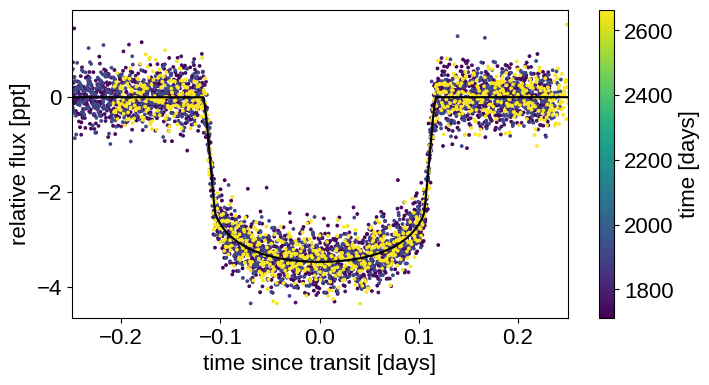
That looks better!
Now on to sampling:
with model:
trace = pmx.sample(
tune=1000,
draws=1000,
start=map_soln,
chains=2,
cores=2,
return_inferencedata=True,
random_seed=[286923464, 464329682],
)
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [b, log_dur, t0, log_period, log_ror, log_rho_gp, log_sigma_gp, sigma, u, mean]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 72 seconds.
Then we can take a look at the summary statistics:
import arviz as az
az.summary(trace)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| mean | 0.261 | 0.094 | 0.101 | 0.454 | 0.002 | 0.002 | 1563.0 | 997.0 | 1.0 |
| log_sigma_gp | -0.797 | 0.145 | -1.046 | -0.508 | 0.003 | 0.002 | 1972.0 | 1202.0 | 1.0 |
| log_rho_gp | -0.559 | 0.190 | -0.890 | -0.176 | 0.004 | 0.003 | 1835.0 | 1252.0 | 1.0 |
| log_ror | -2.901 | 0.007 | -2.915 | -2.888 | 0.000 | 0.000 | 1230.0 | 737.0 | 1.0 |
| log_period | 1.814 | 0.000 | 1.814 | 1.814 | 0.000 | 0.000 | 1763.0 | 1377.0 | 1.0 |
| t0 | 1712.662 | 0.000 | 1712.662 | 1712.662 | 0.000 | 0.000 | 2044.0 | 1414.0 | 1.0 |
| log_dur | -1.503 | 0.002 | -1.507 | -1.499 | 0.000 | 0.000 | 1644.0 | 1303.0 | 1.0 |
| u[0] | 0.299 | 0.070 | 0.170 | 0.428 | 0.002 | 0.001 | 1686.0 | 999.0 | 1.0 |
| u[1] | 0.179 | 0.098 | 0.004 | 0.367 | 0.002 | 0.002 | 1726.0 | 1145.0 | 1.0 |
| sigma | 0.187 | 0.007 | 0.174 | 0.199 | 0.000 | 0.000 | 1744.0 | 1269.0 | 1.0 |
| ror | 0.055 | 0.000 | 0.054 | 0.056 | 0.000 | 0.000 | 1230.0 | 737.0 | 1.0 |
| period | 6.135 | 0.000 | 6.135 | 6.135 | 0.000 | 0.000 | 1763.0 | 1377.0 | 1.0 |
| dur | 0.222 | 0.000 | 0.222 | 0.223 | 0.000 | 0.000 | 1644.0 | 1303.0 | 1.0 |
| b | 0.131 | 0.083 | 0.001 | 0.274 | 0.003 | 0.002 | 646.0 | 664.0 | 1.0 |
| rho_circ | 0.330 | 0.013 | 0.305 | 0.346 | 0.000 | 0.000 | 767.0 | 1247.0 | 1.0 |
And plot the posterior covariances compared to the values from Pepper et al. (2019):
import corner
_ = corner.corner(
trace, var_names=["period", "ror", "b"], truths=[6.134980, 0.05538, 0.125]
)
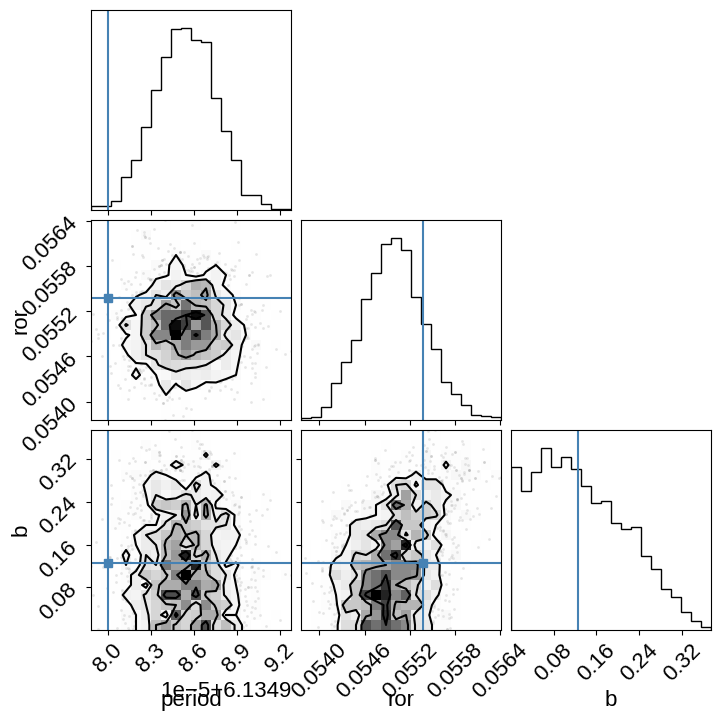
Bonus: eccentricity#
As discussed above, we fit this model assuming a circular orbit which speeds things up for a few reasons. First, setting eccentricity to zero means that the orbital dynamics are much simpler and more computationally efficient, since we don’t need to solve Kepler’s equation numerically. But this isn’t actually the main effect! Instead the bigger issues come from the fact that the degeneracies between eccentricity, arrgument of periasteron, impact parameter, and planet radius are hard for the sampler to handle, causing the sampler’s performance to plummet. In this case, by fitting with a circular orbit where duration is one of the parameters, everything is well behaved and the sampler runs faster.
But, in this case, the planet is actually on an eccentric orbit, so that assumption isn’t justified. It has been recognized by various researchers over the years (I first learned about this from Bekki Dawson) that, to first order, the eccentricity mainly just changes the transit duration. The key realization is that this can be thought of as a change in the implied density of the star. Therefore, if you fit the transit using stellar density (or duration, in this case) as one of the parameters (note: you must have a different stellar density parameter for each planet if there are more than one), you can use an independent measurement of the stellar density to infer the eccentricity of the orbit after the fact. All the details are described in Dawson & Johnson (2012), but here’s how you can do this here using the stellar density listed in the TESS input catalog:
from astroquery.mast import Catalogs
star = Catalogs.query_object("TIC 286923464", catalog="TIC", radius=0.001)
tic_rho_star = float(star["rho"]), float(star["e_rho"])
print("rho_star = {0} ± {1}".format(*tic_rho_star))
# Extract the implied density from the fit
rho_circ = np.repeat(np.asarray(trace.posterior["rho_circ"]).flatten(), 100)
# Sample eccentricity and omega from their priors (the math might
# be a little more subtle for more informative priors, but I leave
# that as an exercise for the reader...)
ecc = np.random.uniform(0, 1, len(rho_circ))
omega = np.random.uniform(-np.pi, np.pi, len(rho_circ))
# Compute the "g" parameter from Dawson & Johnson and what true
# density that implies
g = (1 + ecc * np.sin(omega)) / np.sqrt(1 - ecc**2)
rho = rho_circ / g**3
# Re-weight these samples to get weighted posterior samples
log_weights = -0.5 * ((rho - tic_rho_star[0]) / tic_rho_star[1]) ** 2
weights = np.exp(log_weights - np.max(log_weights))
# Estimate the expected posterior quantiles
q = corner.quantile(ecc, [0.16, 0.5, 0.84], weights=weights)
print(
"eccentricity = {0:.2f} +{1[1]:.2f} -{1[0]:.2f}".format(q[1], np.diff(q))
)
_ = corner.corner(
np.vstack((ecc, omega)).T,
weights=weights,
truths=[0.316, None],
plot_datapoints=False,
labels=["eccentricity", "omega"],
)
rho_star = 0.121689 ± 0.0281776
eccentricity = 0.46 +0.24 -0.13
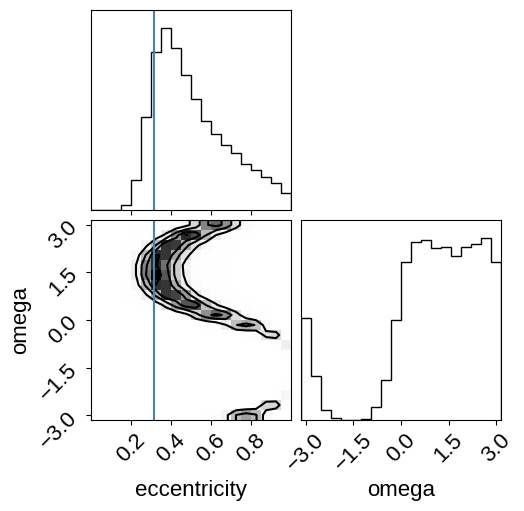
As you can see, this eccentricity estimate is consistent (albeit with large uncertainties) with the value that Pepper et al. (2019) measure using radial velocities and it is definitely clear that this planet is not on a circular orbit.
Citations#
As described in the citation tutorial, we can use citations.get_citations_for_model to construct an acknowledgement and BibTeX listing that includes the relevant citations for this model.
with model:
txt, bib = xo.citations.get_citations_for_model()
print(txt)
This research made use of \textsf{exoplanet} \citep{exoplanet:joss,
exoplanet:zenodo} and its dependencies \citep{celerite2:foremanmackey17,
celerite2:foremanmackey18, exoplanet:agol20, exoplanet:arviz,
exoplanet:astropy13, exoplanet:astropy18, exoplanet:kipping13,
exoplanet:luger18, exoplanet:pymc3, exoplanet:theano}.
print(bib.split("\n\n")[0] + "\n\n...")
@article{exoplanet:joss,
author = {{Foreman-Mackey}, Daniel and {Luger}, Rodrigo and {Agol}, Eric
and {Barclay}, Thomas and {Bouma}, Luke G. and {Brandt},
Timothy D. and {Czekala}, Ian and {David}, Trevor J. and
{Dong}, Jiayin and {Gilbert}, Emily A. and {Gordon}, Tyler A.
and {Hedges}, Christina and {Hey}, Daniel R. and {Morris},
Brett M. and {Price-Whelan}, Adrian M. and {Savel}, Arjun B.},
title = "{exoplanet: Gradient-based probabilistic inference for
exoplanet data \& other astronomical time series}",
journal = {arXiv e-prints},
year = 2021,
month = may,
eid = {arXiv:2105.01994},
pages = {arXiv:2105.01994},
archivePrefix = {arXiv},
eprint = {2105.01994},
primaryClass = {astro-ph.IM},
adsurl = {https://ui.adsabs.harvard.edu/abs/2021arXiv210501994F},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
...